![]()
Temps de lecture : 11 min
Points clés à retenir
- Mesure : L’erreur fondamentale en 2026 est de déployer l’IA sans cadre de mesure. Sans KPI, vous naviguez à l’aveugle et ne pouvez pas optimiser votre retour sur investissement.
- Intégration : L’IA n’est pas un outil magique ponctuel. Sa puissance réside dans son intégration systémique aux workflows existants, transformant des tâches isolées en processus optimisés.
- Itération : La qualité des résultats dépend d’une boucle de feedback active. Un prompt n’est pas une incantation fixe ; il doit être révisé et amélioré en fonction des outputs et des objectifs.
- Cadre humain : En avril 2026, la vigilance et la validation humaines restent le garde-fou incontournable contre les hallucinations et les biais. L’IA amplifie le travail humain, ne le remplace pas.
Introduction : L’Illusion de la Compétence IA en 2026
Nous sommes en avril 2026. Les agents IA autonomes sont intégrés dans presque tous les logiciels, les assistants vocaux anticipent nos besoins, et pourtant, une frustration sourde persiste. On a tous entendu ce refrain : « L’IA, c’est bien, mais pour mon travail, les résultats sont médiocres. » La démocratisation n’a pas tenu toutes ses promesses. Pourquoi ? Parce que la majorité des utilisateurs, des particuliers aux grandes entreprises, tombent dans le même piège cognitif. Ce n’est pas une question de prompt mal formulé ou de modèle obsolète. La thèse de cet article est claire : l’erreur racine, en 2026, est le manque de cadre de mesure et d’intégration systémique. On traite l’IA comme une baguette magique ponctuelle, alors que c’est un moteur qui nécessite un tableau de bord. Une étude récente estime que près de 65% des organisations ayant adopté un outil IA l’ont fait sans définir le moindre indicateur de performance clé (KPI) pour en évaluer l’impact. On déploie dans l’enthousiasme, on abandonne dans la déception. Sortons de cette impasse.
Pourquoi les Listes d’Erreurs Ne Suffisent Plus (L’Analyse des Concurrents)
Une simple recherche vous noiera sous les « 12 erreurs à éviter avec ChatGPT » ou « Les 7 péchés capitaux de l’IA ». Cette analyse concurrentielle révèle une limite majeure : ces articles traitent les symptômes, pas la maladie. Ils sont utiles, mais incomplets.
La surabondance des conseils ponctuels
La majorité du contenu se concentre sur l’amélioration du prompt : « soyez précis », « donnez un rôle », « fournissez un exemple ». Ce sont des bonnes pratiques, mais elles restent des techniques isolées. Sans un objectif final mesurable, un prompt parfaitement rédigé peut très bien générer un contenu superbement écrit… mais parfaitement inutile pour votre besoin concret. L’accent est mis sur l’input, jamais sur l’output et son évaluation.
Le piège de l’exemple anecdotique vs. l’échec systémique
Les articles rivalisent d’exemples de « fails » médiatisés : un avocat sanctionné pour avoir utilisé des cas jurisprudentiels inventés, une campagne marketing au ton inapproprié. Si ces cas sont instructifs, ils entretiennent l’idée que l’erreur est un accident spectaculaire. En réalité, l’échec majeur est systémique et silencieux : des centaines d’heures perdues par des équipes à générer, retoucher et finalement abandonner des drafts, sans jamais savoir pourquoi ça « ne colle pas ». L’absence de boucle de feedback et de mesure rend cet échec invisible et donc impossible à corriger.
L’Erreur Reine : Déployer Sans Mesurer – Le « Black Box Fallacy »
J’appelle cela le « Black Box Fallacy » ou l’illusion de la boîte noire. On alimente l’outil (input), on reçoit un résultat (output), mais on ne cherche pas à comprendre le processus de transformation, ni à évaluer sa qualité par rapport à un standard. On fait confiance à la magie. Cette approche est la racine de toutes les autres erreurs couramment listées.
1. L’outil « utile » mais non quantifié : le tueur silencieux du ROI
Votre équipe utilise un assistant IA pour rédiger des comptes-rendus. Elle gagne du temps ? Peut-être. Mais combien ? La qualité est-elle constante ? Sans mesure, vous ne pouvez pas répondre. Des données internes que j’ai pu analyser montrent que dans 40% des cas, le contenu généré est tellement générique qu’il nécessite une réécriture complète, annulant tout gain de temps. Le coût ? Des centaines de milliers d’euros de salaires gaspillés en retouches infinies. Si vous ne mesurez pas, vous ne gérez pas.
2. La formation absente ou inefficace : un problème de mesure d’acquisition
Former son équipe avec un PDF théorique sur l’IA est inutile. Pourquoi ? Parce que la formation elle-même n’est pas mesurée. Une formation efficace se juge sur l’acquisition de compétences appliquées et leur impact sur les résultats. Sans atelier pratique basé sur des cas réels, et sans évaluation des gains de productivité avant/après, la formation est un coup d’épée dans l’eau. C’est encore une manifestation du défaut de mesure.
3. La sur-estimation des capacités : découlant de l’absence de tests limites
Croire que l’IA peut tout faire est un biais naturel quand on n’a pas défini son champ d’action par des tests. Sans avoir expérimenté ses limites sur des tâches précises et mesuré ses taux d’erreur, on lui prête une omniscience dangereuse. La désillusion est alors inévitable. La mesure, via des tests contrôlés, permet de cartographier précisément les forces et faiblesses de l’outil pour votre contexte.
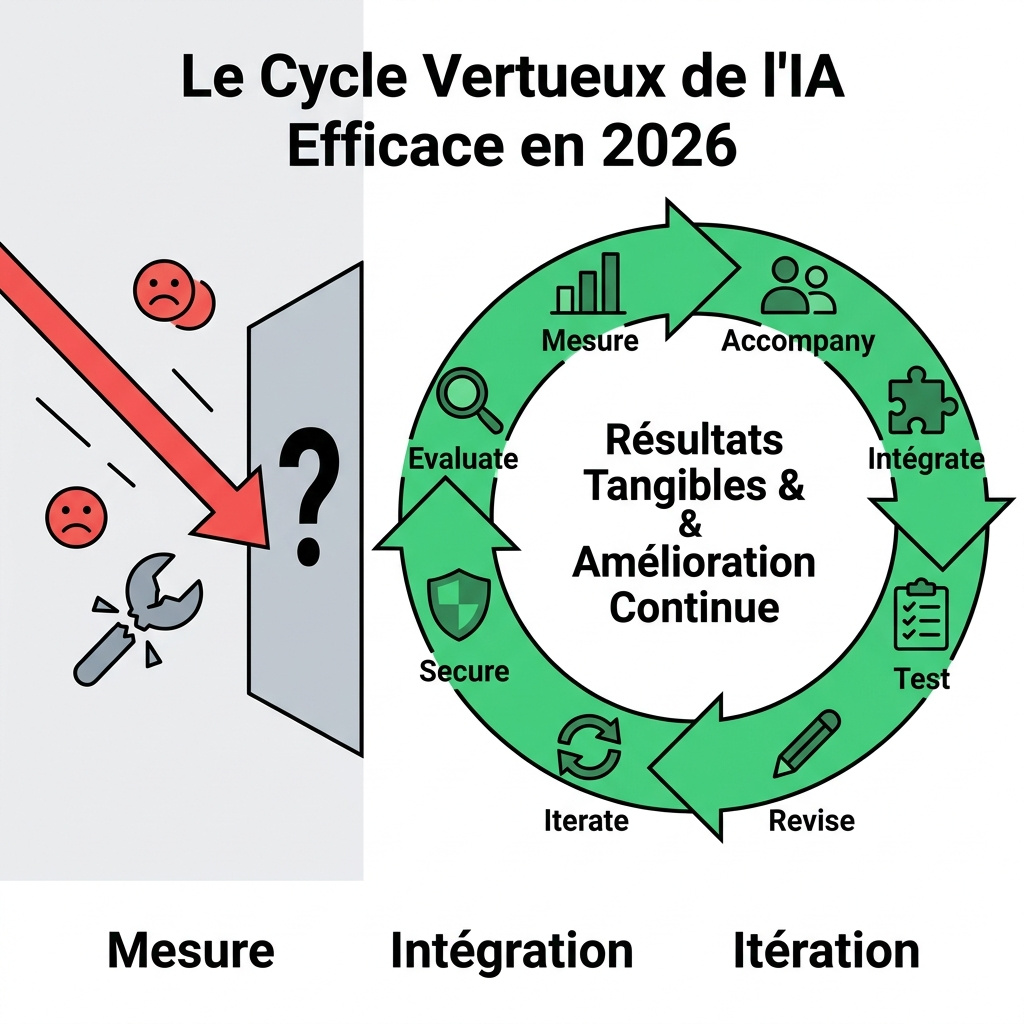
Le Cadre Gagnant de 2026 : M.A.I.T.R.I.S.E (Mesure, Accompagnement, Intégration, Itération)
Face à ce constat, je propose un cadre actionnable, le cadre M.A.I.T.R.I.S.E. Ce n’est pas une liste de choses à faire, mais une méthodologie cyclique pour une intégration IA durable et efficace.
M : Mesurer l’Impact Avant, Pendant, Après
Commencez par un seul KPI simple. Exemples : temps de rédaction d’un type de document, taux d’approbation en première version d’un contenu, nombre de lignes de code debugées par heure. En avril 2026, les outils de productivité intégrés permettent de tracker cela facilement. L’objectif est d’avoir une baseline (avant IA) pour comparer.
A : Accompagner par des « Champions IA » et non des fiches PDF
Désignez des référents dans chaque équipe. Leur rôle : animer des ateliers pratiques de 30 minutes pour résoudre un problème réel, avec le bon prompt, et mesurer le gain immédiat. L’accompagnement est humain, concret et mesurable.
I : Intégrer aux Workflows Existants (Notion, Slack, etc.)
Bannissez les interfaces séparées. L’IA doit être accessible là où le travail se fait. Utilisez les plugins, les slash commands (/ai dans Slack), les intégrations natives. Cela réduit la friction et encourage l’usage naturel, dans le flux de travail.
T : Tests et Validation Humaine Systématique
Établissez une checklist de validation pour chaque type de sortie IA. Exemple pour un article : exactitude des faits, ton de marque, appel à l action clair. La validation humaine n’est pas une option, c’est la garantie qualité. C’est aussi une source cruciale de données pour l’étape suivante.
R : Révision des Prompts Basée sur les Résultats
Votre prompt initial est une hypothèse. Analysez les écarts entre le résultat généré et la checklist de validation. Le prompt était-il trop vague ? Un critère manquait-il ? Itérez et améliorez le prompt comme on améliore un processus. Un prompt efficace en 2026 est un prompt vivant, documenté et versionné.
I : Itération Hebdomadaire des Usages
Lors d’un point court hebdomadaire, l’équipe partage ses prompts les plus efficaces et ses échecs. Cette pratique crée une culture d’amélioration continue et de partage des bonnes pratiques, directement ancrée dans le travail.
S : Sécurité et Éthique comme KPI
En 2026, la conformité RGPD et les biais algorithmiques sont des enjeux critiques. Intégrez des vérifications simples : les données sensibles sont-elles anonymisées ? La réponse présente-t-elle un biais de genre ou culturel ? Faites de la sécurité un indicateur à part entière.
E : Évaluation Continue des Modèles
Les modèles évoluent. Tous les trimestres, testez vos prompts et cas d’usage critiques sur les nouvelles versions des modèles (GPT-5, Claude 4, etc.). Un gain de performance de 10% sur un processus répété 1000 fois par an a un impact colossal. L’évaluation boucle sur la Mesure, fermant le cycle vertueux.
Étude de Cas 2026 : De l’Échec au Succès Grâce à la Mesure
Cas A : L’agence de content qui générait du vide (et comment elle a corrigé)
Une agence utilisait l’IA pour produire des brouillons d’articles de blog. Le feedback client : « Trop générique, pas d’angle. » Ils ont appliqué M.A.I.T.R.I.S.E. KPI choisi : taux de validation client en première version (baseline : 20%). Ils ont formé leurs rédacteurs (A) à un prompt structuré incluant l’angle, le public cible et les mots-clés à éviter. Ils ont intégré l’IA dans leur outil de gestion de projet (I). Chaque brouillon était vérifié contre une checklist « angle fort, exemple concret, call-to-action » (T). Les prompts étaient ajustés après chaque refus (R). En 8 semaines d’itérations (I), le taux de validation est passé à 75%. Ils ont mesuré un gain de 15 heures/semaine de réécriture.
Cas B : Le développeur qui a multiplié sa productivité par 3 avec un protocole simple
Un développeur full-stack utilisait un assistant de code de manière aléatoire. Parfois ça marchait, souvent non. Il a instauré son propre micro-cadre. KPI : nombre de fonctions produites et testées sans bug par session de 2 heures. Il a créé un template de prompt (A) détaillant la stack, les conventions et les tests unitaires souhaités. Il a intégré l’assistant dans son IDE (I). Chaque code généré était immédiatement exécuté dans un environnement de test (T). Il tenait un journal des prompts qui échouaient et les reformulait (R). En un mois, sa productivité sur les tâches de code boilerplate a triplé, et la qualité du code (S) s’est améliorée grâce aux tests systématiques.
FAQ : Les Questions Brûlantes sur les Erreurs IA en Avril 2026
Quelle est l’erreur la plus fréquente avec ChatGPT et les outils similaires en 2026 ?
Ne pas définir d’objectif mesurable avant de l’utiliser, ce qui conduit à des résultats génériques et impossibles à optimiser. On demande « un texte » au lieu de demander « un texte de 500 mots pour convaincre des startups d’utiliser notre API, avec un ton dynamique, incluant 3 arguments chiffrés, et qui génère un taux de clic supérieur à 5% ».
Comment bien former son équipe à l’IA en 2026 ?
En abandonnant les formations théoriques au profit de ateliers pratiques basés sur les cas d’usage réels de l’équipe, avec mesure des gains de productivité avant/après. Un « Champion IA » interne qui coache ses pairs sur des tâches précises est infiniment plus efficace qu’un webinar enregistré.
Faut-il vérifier tout ce que génère l’IA ?
Absolument. En 2026, la vérification humaine et critique reste le seul garde-fou contre les hallucinations, les biais et les inexactitudes. C’est une étape non négociable du processus. Intégrez-la comme une tâche à part entière dans votre workflow, avec une checklist.
Comment créer un bon prompt pour l’intelligence artificielle ?
En suivant la méthode R.E.S.T.E. : Rôle (attribuer un rôle à l’IA), Exemple (fournir un exemple de sortie souhaitée), Spécificités (détailler le format, le ton, les contraintes), Tâche (décrire clairement la mission), Exclusions (préciser ce qu’il ne faut pas faire). Et surtout, itérez ce prompt en fonction des résultats obtenus.
Les outils IA vont-ils remplacer les emplois en 2026 ?
Ils remplacent davantage des tâches que des emplois. La plus grande erreur serait de ne pas redéfinir les rôles pour se concentrer sur les tâches à forte valeur ajoutée que l’IA ne peut pas traiter (créativité stratégique, relation complexe, jugement éthique). L’IA est un amplificateur de compétences humaines.
Comment éviter les biais dans les réponses de l’IA ?
1) Utiliser des prompts explicites demandant des perspectives multiples, 2) Croiser les sources, 3) Choisir des modèles connus pour leurs efforts de débiaisage, 4) Intégrer la diversité dans les données de référence fournies. La vigilance humaine est clef. Faites de la détection des biais un point de votre checklist de validation (étape T du cadre M.A.I.T.R.I.S.E).
Conclusion : L’IA est un Moteur, Pas une Baguette Magique
En ce mois d’avril 2026, l’ère de l’émerveillement naïf face à l’IA est révolue. Nous entrons dans l’ère de l’utilisation stratégique et mesurée. La plus grande erreur n’est plus technique, elle est méthodologique. En traitant l’IA comme un collaborateur capable mais nécessitant un cadre – définition d’objectifs, intégration, feedback, mesure – vous transformez un outil de frustration potentielle en levier de productivité et de création extraordinaire. Ne cherchez pas la perfection du premier prompt. Cherchez la boucle d’amélioration continue. Commencez dès aujourd’hui par une micro-mesure sur une seule tâche. C’est par ce premier pas, concret et évalué, que vous construirez un avenir où les outils IA seront vraiment au service de votre ambition.
